
Python Face Clustering - 얼굴 클러스터링
이전에 포스트했던 Python Face Recognition은 웹캠으로 입력받은 비디오에서 이미 알고 있는 얼굴과 비슷한 얼굴을 찾는 예제를 소개했습니다. 모르는 사람의 얼굴은 unknown으로 표시했습니다. 여기서 한 발 더 나아가 unknown 얼굴을 더 활용할 방법이 있는데, 바로 Face Clustering입니다. Face Clustering은 임의의 얼굴을 비슷한 얼굴끼리 모으고 분류하는 기술입니다.
이 글은 이 사이트에서 많은 부분을 참고하였습니다 - Face Clustering with Python in PyImageSearch site
Face clustering은 주어진 얼굴들을 비슷한 얼굴끼리 모으고 분류합니다. 기준이 되는 얼굴이나 몇 명의 얼굴이 존재하는지에 대한 정보도 없는 데도 말이죠. 이런 면에서, face clustering은 unsupervised learning 입니다. Clustering이란 이름에서 알 수 있듯이, k-NN, k-mean 등의 clustering을 사용할 수 있지만, 분류해야 하는 사람의 수를 모르기 때문에, DBSCAN이나 Chinese whispers clustering 알고리즘을 사용합니다.
여기에서는 python을 이용하여 face clustering을 구현해 보겠습니다. Source code는 아래 GitHub에서 다운로드 받을 수 있습니다.
https://github.com/ukayzm/opencv/tree/master/face_clustering
Implementation
대충 감이 오셨겠지만, face clustering은 (1) 인식된 얼굴을 (2) 분류하는 것입니다. 즉, 크게 두 단계로 나눌 수 있습니다.
(1) Face Recognition - 얼굴 인식하기
(2) Face Clustering - 인식된 얼굴 분류하기
(1) Face Recognition
얼굴을 인식하는 것은 이전 글인 Face Recognition에서 사용한 방법과 동일합니다. Python의 face_recognition 패키지를 이용하여 쉽게 구현할 수 있습니다.
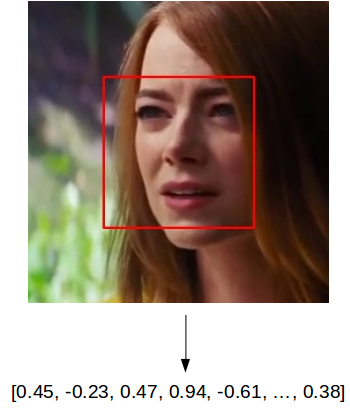
동영상에서 이미지를 읽어서, 얼굴을 인식한 다음, 아래 그림과 같이 128 크기의 vector로 수치화 합니다. Vector는 미리 학습시킨 신경망을 통과시켜 얻습니다. 그래서, vector의 각 숫자가 어떤 의미를 가지는지는 알 수 없습니다. 다만, 비슷한 얼굴을 입력하면 비슷한 결과가 나온다는 것은 알 수 있습니다.
전체 소스 코드 중에서, face recognition 부분만 요약한 것이 아래 코드 입니다. (실제 코드는 이것보다 좀 더 복잡하죠.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import face_recognition
def encode(self, src_file, capture_per_second, stop=0):
src = cv2.VideoCapture(src_file)
self.faces = []
frame_id = 0
frame_rate = src.get(5)
frames_between_capture = int(round(frame_rate) / capture_per_second)
while True:
ret, frame = src.read()
frame_id += 1
if frame_id % frames_between_capture != 0:
continue
rgb = frame[:, :, ::-1]
boxes = face_recognition.face_locations(rgb, model="hog")
encodings = face_recognition.face_encodings(rgb, boxes)
faces_in_frame = []
for box, encoding in zip(boxes, encodings):
face = Face(frame_id, None, box, encoding)
faces_in_frame.append(face)
self.drawBoxes(frame, faces_in_frame)
pathname = os.path.join(self.capture_dir,
self.capture_filename(frame_id))
cv2.imwrite(pathname, frame)
self.faces.extend(faces_in_frame)
line 1
얼굴 인식은 face_recognition 패키지를 이용합니다.
line 4-8
src_file을 열고, 변수를 초기화 합니다. src_file은 동영상 파일이 될 수도 있고, web cam을 지정하면 실시간으로 얼굴을 인식할 수도 있습니다.
line 11-14
src로부터 얼굴을 인식할 그림을 한 장 읽어옵니다. 모든 그림으로부터 얼굴을 인식하려면 시간이 많이 걸리므로, frames_between_capture마다 한 장씩만 인식합니다.
line 16-18
OpenCV는 그림이 BGR로 저장되므로, 이것을 RGB로 바꿉니다.
face_recognition.face_locations() 함수를 호출하여 그림으로부터 얼굴 영역을 얻어냅니다. 이 예제에서는 HOG 알고리즘을 사용하는데, 신경망을 이용한 CNN을 사용하면 인식 속도가 더 느린 대신에 더 정확하게 인식할 수 있습니다. boxes에는 (top, right, bottom, left)의 리스트가 담겨 있는데, 이 box는 인식된 얼굴의 좌표를 나타냅니다.
face_recognition.face_encodings() 함수를 호출하면 얼굴 영역을 128 크기의 vector로 변환합니다. 그림 안에 있는 모든 얼굴이 변환되어 encodings 변수에 담기게 됩니다.
이 두 함수 호출이 얼굴 인식의 핵심입니다.
line 20-23
이렇게 얻은 boxes와 encodings를 faces_in_frame 변수에 저장합니다.
line 25-28
원본 그림에 얼굴 영역을 그리고, 파일로 저장합니다. 저장된 파일은 나중에 clustering한 결과를 보여줄 때 사용됩니다.
line 30
self.faces 에는 모든 얼굴 인식 결과가 담깁니다.
(2) Face Clustering
인식된 얼굴을 분류하는 DBSCAN 알고리즘은 Scikit-learn 패키지에 이미 구현되어 있습니다. 우리는 이것을 가져다 쓰기만 하면 되죠.
위와 마찬가지로, 아래 코드는 clustering 부분을 요약한 것입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from sklearn.cluster import DBSCAN
def cluster(self):
encodings = [face.encoding for face in self.faces]
clt = DBSCAN(metric="euclidean")
clt.fit(encodings)
label_ids = np.unique(clt.labels_)
num_unique_faces = len(np.where(label_ids > -1)[0])
for label_id in label_ids:
dir_name = "ID%d" % label_id
os.mkdir(dir_name)
indexes = np.where(clt.labels_ == label_id)[0]
for i in indexes:
frame_id = self.faces[i].frame_id
box = self.faces[i].box
pathname = os.path.join(self.capture_dir,
self.capture_filename(frame_id))
image = cv2.imread(pathname)
face_image = self.getFaceImage(image, box)
filename = dir_name + "-" + self.capture_filename(frame_id)
pathname = os.path.join(dir_name, filename)
cv2.imwrite(pathname, face_image)
line 1
Clustering 알고리즘은 Scikit-learn 패키지에 구현되어 있습니다.
line 4
self.faces에 저장되어 있던 encodings를 추출합니다. 여기에는 위에서 인식한 모든 얼굴 영역에 대한 encoding이 저장되어 있습니다.
line 6-7
encodings를 clustering 합니다. 네. Clustering이 끝났습니다. 순식간에요. 좀 싱겁죠? 이제 clustering한 결과를 잘 이용하면 됩니다.
line 9-10
Clustering을 하면 비슷한 encoding끼리 분류하고, 각 그룹에 0부터 label을 매깁니다. -1은 분류되지 않은 encoding (즉, 비슷한 얼굴이 없는…)에 매겨지는 label 입니다.
말이 좀 어려운데요. 예를 들어 La La Land 영화를 clustering한다면, “Ryan Gosling” 얼굴에는 label 0, “Emma Stone” 얼굴에는 label 1이 매겨지는 식이죠.
label_ids에는 각 label이 저장되고, num_unique_faces에는 분류된 label의 갯수가 저장됩니다.
line 12
각 label에 대해서 아래 부분을 수행합니다.
line 13-14
label 이름으로 디렉토리를 만듭니다. 이 디렉토리에는 label에 해당하는 얼굴 그림이 저장될 것입니다.
line 16
label에 해당하는 index를 모두 얻어옵니다. Clustering은 encodings에 대해서 했고 (line 7), encodings는 self.faces로부터 추출한 것이므로 (line 4), 결과적으로 indexes는 self.faces 중에서 동일한 얼굴로 분류된 모든 index가 됩니다.
18-27
label에 해당하는 모든 얼굴을 ID# 디렉토리에 저장합니다.
Try It
동영상에 나오는 얼굴을 분류
아래 동영상을 이용하여, 실제 코드를 돌려 보았습니다.
youtube-dl을 이용하여 동영상을 다운받은 다음, 아래 명령을 내리면 됩니다.
$ youtube-dl https://www.youtube.com/watch?v=bUQj7Ng7PCs
$ python face_clustering.py -e "I Ran - Pool Party Scene [La La Land_2016] - 1080p Blu-ray-bUQj7Ng7PCs.mkv"
아래 분류된 얼굴을 보세요. 일부 잘못 분류된 것도 있지만, 꽤 괜찮은 결과를 보이죠? 심지어 선글래스를 쓴 얼굴도 분류하네요.
ID 0

ID 1

ID 2

ID 3

ID 4

ID 5

ID 6

ID 7

ID 8

ID -1 (unknown)

Web cam을 이용하여 분류
$ python face_clustering.py -e 0
위와 같은 명령을 내리면 동영상이 아닌 web cam 영상에서 얼굴을 추출합니다. 실행 시킨 후, 주위 사람들을 웹캠 앞으로 모아보세요. 충분한 양의 프레임이 얻어지면 ^C를 눌러 추출을 중단합니다. 이후, 자동으로 분류 작업이 수행되고, 분류된 얼굴이 디렉토리별로 저장됩니다.
조금 더 응용해 볼까요? 감시 카메라 영상을 입력하면 어떨까요? 소스 코드를 조금 수정하면, 몇 명의 사람이 언제 얼마동안 화면에 나타났는지 알아낼 수도 있겠죠?
References
Source Code Download
https://github.com/ukayzm/opencv/tree/master/face_clustering
See Also
Unknown Face Classifier에서는 클러스터링이 아니라 간단한 알고리즘만으로 모르는 사람의 얼굴을 실시간으로 분류하는 방법을 소개합니다. 분류된 사람의 정보를 저장했다가 다음번 실행할 때 재활용하고, 얼굴을 재분류하여 정확도를 높일 수도 있습니다. 꼭 한 번 읽어보시기를 강력히 추천합니다.