
Training on the Pet Dataset - 펫 데이터셋 학습시키기
구글은 object detection model을 이용하여 Pet Dataset을 학습시키는 예제를 제공하고 있습니다. 예제는 Google Cloud Platform 상에서 학습을 시키도록 되어 있는데, 여기서는 local PC에서 학습 시키는 방법을 설명합니다. 그리고, Google의 예제에서 잘못된 부분을 고치고, 예제 실행시 만나는 문제의 해결책을 제시합니다.
시작하기
이 예제에서는 실제로 제가 사용한 디렉토리 이름을 그대로 사용했고 매 단계마다 작업 디렉토리를 명시하였으므로, 좀 더 실용적인 예제가 될 것으로 기대합니다.
디렉토리
이 예제에서 사용할 디렉토리는 아래와 같습니다.
- Home directory:
/home/rostude - Tensorflow model directory:
/home/rostude/work/tensorflow/models - Pet training directory:
/home/rostude/work/pet-training
아래 예제를 적용할 때는, 디렉토리 이름을 자신의 환경에 맞게 적당히 수정해야 합니다.
TensorFlow Models
TensorFlow model이 설치되어 있어야 합니다. 설치 방법은 여기를 참고하세요.
이 글을 작성 중이던 6월 6일 경에 GitHub의 tensorflow/models에 큰 변화가 있었습니다. 그 영향 때문인지, 6월 6일 코드로 create_pet_tf_record.py를 실행하면 pet_train.record, pet_val.record 파일이 예제와 다르게 생성되었습니다. 그래서, 저는 아래와 같이 6월 4일 code로 rollback 하여 테스트를 하였습니다. 자신이 가지고 있는 TensorFlow Model이 6월 4일 이전 버전이면 상관 없습니다.
$ cd /home/rostude/work/tensorflow/models/
$ git checkout 772964e --
Pet Dataset
이 예제에서 사용할 Pet Dataset이 어떤 것인지 http://www.robots.ox.ac.uk/~vgg/data/pets/를 방문하여 대략 훑어보세요.
사전작업
아래와 같이, training을 시킬 디렉토리를 만듭니다.
$ mkdir -p ~/work/pet-training
$ mkdir -p ~/work/pet-training/data # for data, model and config
$ mkdir -p ~/work/pet-training/download # for downloaded files
Download
Pet dataset image, annotation을 다운로드 받습니다. 그리고, Google이 공개한 Faster RCNN 모델을 다운로드 받습니다. Faster RCNN 모델을 기반으로 Pet dataset을 학습시킬 것입니다.
$ cd ~/work/pet-training/download
$ wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
$ wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
$ tar -xvf images.tar.gz
$ tar -xvf annotations.tar.gz
$ wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
$ tar -xvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz
Data
구글이 제공하는 예제 Label 파일을 복사해 넣습니다. Lebel 파일은 분류할 개/고양이의 품종 이름이 들어 있는 protobuf 형식의 파일 입니다.
$ cd ~/work/pet-training/data
$ cp ~/work/tensorflow/models/research/object_detection/data/pet_label_map.pbtxt .
$ cat ~/work/pet-training/data/pet_label_map.pbtxt
item {
id: 1
name: 'Abyssinian'
}
item {
id: 2
name: 'american_bulldog'
}
...
Object detection은 training이나 evaluation을 하기 위한 데이터로 TFRecord 형식의 파일을 입력으로 받습니다. 그래서, 위에서 다운받은 Pet dataset과 레이블을 조합하여 TFRecord 형식의 파일을 만들어 주어야 합니다. 파일 변환하는 툴은 구글에서 제공하고 있으니, 그것을 그대로 사용합니다.
$ python ~/work/tensorflow/models/research/object_detection/dataset_tools/create_pet_tf_record.py \
--label_map_path=./pet_label_map.pbtxt \
--data_dir=../download \
--output_dir=`pwd`
$ ls
pet_label_map.pbtxt pet_train_with_masks.record pet_val_with_masks.record
create_pet_tf_record.py를 실행시키면 위와 같이, pet_train_with_masks.record, pet_val_with_masks.record 파일이 생성됩니다. 그런데, 이 파일 이름을 아래와 같이 pet_train.record, pet_val.record로 바꿔 주어야만 이후 단계에서 에러가 발생하지 않습니다.
$ mv pet_train_with_masks.record pet_train.record
$ mv pet_val_with_masks.record pet_val.record
$ ls
pet_label_map.pbtxt pet_train.record pet_val.record
Model
$ cd ~/work/pet-training/data
$ cp ../download/faster_rcnn_resnet101_coco_11_06_2017/model* .
Config
$ cd ~/work/pet-training/data
$ cp ~/work/tensorflow/models/research/object_detection/samples/configs/faster_rcnn_resnet101_pets.config .
$ sed -i "s|PATH_TO_BE_CONFIGURED|/home/rostude/work/pet-training/data|g" faster_rcnn_resnet101_pets.config
faster_rcnn_resnet101_pets.config 파일에는 학습을 위한 각종 config가 들어 있습니다. 이 중에서 반드시 해야 하는 것은 PATH_TO_BE_CONFIGURED를 실제 디렉토리 이름으로 바꾸는 것입니다. 위와 같이 sed 명령으로 한번에 바꿔도 되고, vi 로 직접 편집해도 됩니다. 주의할 점은, ~/work/pet-trainig/data 이런 식으로 ~로 시작하는 경로를 지정하면 안되고, /로 시작하는 절대 경로를 사용해야 합니다.
Training and evaluation
이제 준비는 끝났습니다. Training을 시작할 수 있습니다. 참고로, 아래 명령은 아무 디렉토리에서 실행시켜도 됩니다. 여기서도 마찬가지로, 파라미터로 ~로 시작하는 경로를 지정하면 안됩니다.
Training
아래와 같이 python명령으로 Training을 시키킵니다. 주기적으로 로그가 출력됩니다.
$ python ~/work/tensorflow/models/research/object_detection/train.py \
--logtostderr \
--pipeline_config_path=/home/rostude/work/pet-training/data/faster_rcnn_resnet101_pets.config \
--train_dir=/home/rostude/work/pet-training/training
...
INFO:tensorflow:global step 599: loss = 0.9922 (14.020 sec/step)
INFO:tensorflow:global step 600: loss = 0.8763 (16.702 sec/step)
INFO:tensorflow:global step 601: loss = 1.4698 (15.401 sec/step)
INFO:tensorflow:Recording summary at step 601.
INFO:tensorflow:global step 602: loss = 0.3024 (22.146 sec/step)
INFO:tensorflow:global step 603: loss = 0.6957 (18.191 sec/step)
INFO:tensorflow:global step 604: loss = 0.6043 (16.251 sec/step)
INFO:tensorflow:global step 605: loss = 2.1987 (17.995 sec/step)
INFO:tensorflow:global step 606: loss = 0.9268 (17.557 sec/step)
INFO:tensorflow:global step 607: loss = 1.2230 (19.084 sec/step)
INFO:tensorflow:Recording summary at step 607.
INFO:tensorflow:Recording summary at step 607.
INFO:tensorflow:global step 608: loss = 2.8359 (178.634 sec/step)
INFO:tensorflow:global step 609: loss = 0.2520 (49.319 sec/step)
INFO:tensorflow:Saving checkpoint to path /home/rostude/work/pet-training/training/model.ckpt
INFO:tensorflow:global step 610: loss = 0.4853 (63.031 sec/step)
INFO:tensorflow:Recording summary at step 610.
INFO:tensorflow:global step 611: loss = 0.2766 (41.864 sec/step)
INFO:tensorflow:global step 612: loss = 1.2626 (58.015 sec/step)
...
중간에 "Saving checkpoint" 로그가 보이죠? Training 결과를 중간 중간에 저장을 하는 것입니다. 이 기능 때문에, training 중간에 언제든지 ^C를 눌러 중단시켰다가, 동일 명령을 입력하여 training을 재개할 수 있습니다.
Monitoring
터미널을 하나 더 띄워서 아래와 같이 tensorboard를 실행시키고 web browser에서 “localhost:6006”을 띄우면 진행 과정을 모니터링 할 수 있습니다.
$ tensorboard --logdir=/home/rostude/work/pet-training/
아래 그림은 2일간 학습을 시킨 Total Loss 그래프 입니다. 주말 내내 학습을 시킨 것인데, GPU로 학습 시키면 한 두 시간 정도만 학습을 시켜도 쓸만한 결과가 나올 것 같습니다.
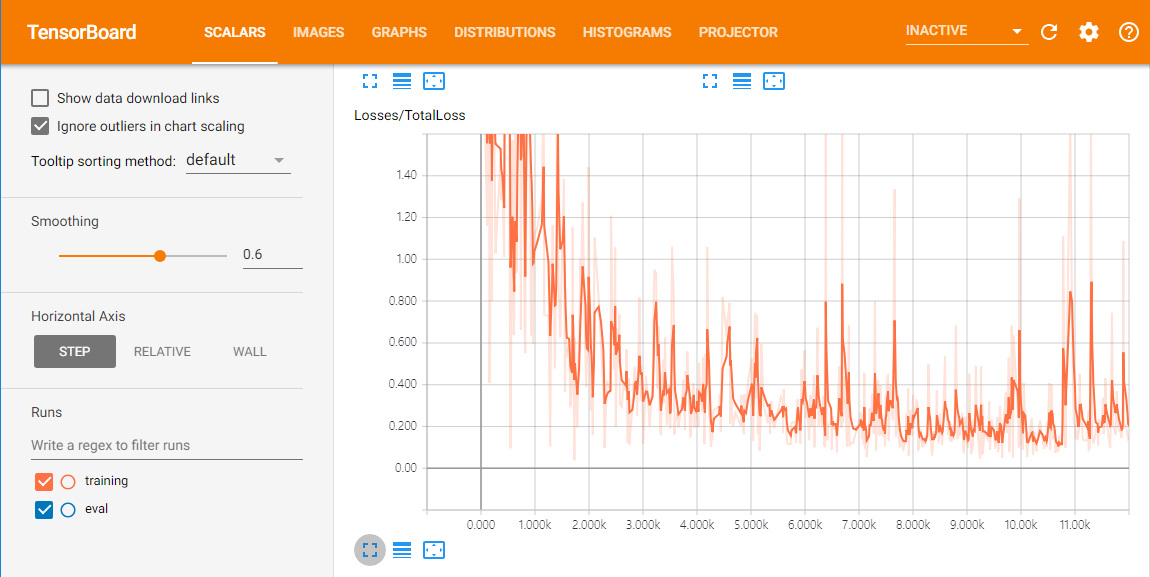
Evaluation
학습이 잘 진행되는지 검증하기 위해, 터미널을 하나 더 띄워서 아래와 같이 evaluation을 실행합니다.
$ python ~/work/tensorflow/models/research/object_detection/eval.py \
--logtostderr \
--pipeline_config_path=/home/rostude/work/pet-training/data/faster_rcnn_resnet101_pets.config \
--checkpoint_dir=/home/rostude/work/pet-training/training \
--eval_dir=/home/rostude/work/pet-training/eval
구글의 Guide에서는 training과 evaluation을 동시에 실행시켜도 된다고 되어 있습니다. 하지만 제 노트북에서 실행시켜보니, evaluation을 실행하면 컴퓨터가 매우 느려졌습니다. 그래서, 저는 ^C로 training을 중단 시키고 evaluation을 실행시켰습니다.
Evaluation을 실행시키면, tensorboard에 image tab이 생기고, 아래 그림과 같이 학습 결과를 눈으로 확인할 수 있습니다. 제 경우는 대략 500 step의 training을 돌고 난 후부터 한 두개 이미지씩 인식을 하기 시작했습니다.
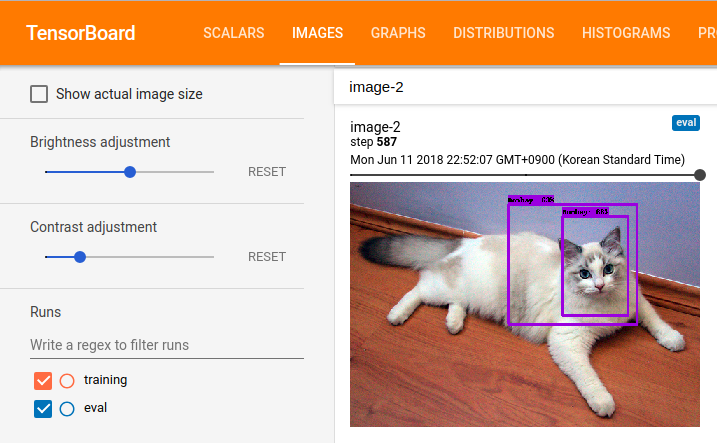
Checkpoint and Frozen Graph
충분히 학습을 시켰다고 생각되면, 이제 학습을 중단시키고 학습된 모델을 export해야 합니다. Export된 모델은 이 예제에 그대로 적용할 수 있습니다.
아래와 같이, Checkpoint가 생성된 것을 확인할 수 있습니다. 이 Checkpoint를 frozen graph로 export 하는 것입니다. training 디렉토리에서 ls를 해 보면, 아래와 같이 여러개의 checkpoint 파일 (model.ckpt-XXXX.* 파일)이 보입니다. 이 중에서 XXXX의 숫자가 가장 큰 것이 마지막으로 생성된 checkpoint 파일입니다.
export_inference_graph.py를 실행시킬 때, --trained_checkpoint_prefix 파라미터에 XXXX 숫자를 틀리지 않게 지정해야 합니다. 아래 예에서는 21475가 사용되었습니다. 각자 생성된 checkpoint에 따라 알맞는 XXXX를 사용하세요.
$ cd ~/work/pet-training/training
$ ls
checkpoint model.ckpt-21310.index
events.out.tfevents.1528331021.a42 model.ckpt-21310.meta
events.out.tfevents.1528336914.a42 model.ckpt-21365.data-00000-of-00001
events.out.tfevents.1528418824.a42 model.ckpt-21365.index
events.out.tfevents.1528419447.a42 model.ckpt-21365.meta
events.out.tfevents.1528419623.a42 model.ckpt-21420.data-00000-of-00001
events.out.tfevents.1528448067.a42 model.ckpt-21420.index
events.out.tfevents.1528680565.a42 model.ckpt-21420.meta
graph.pbtxt model.ckpt-21475.data-00000-of-00001
model.ckpt-21254.data-00000-of-00001 model.ckpt-21475.index
model.ckpt-21254.index model.ckpt-21475.meta
model.ckpt-21254.meta pipeline.config
model.ckpt-21310.data-00000-of-00001
$ python ~/work/tensorflow/models/research/object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path ../data/faster_rcnn_resnet101_pets.config \
--trained_checkpoint_prefix=./model.ckpt-21475 \
--output_directory ../freeze
$ ls ../freeze/
checkpoint model.ckpt.data-00000-of-00001 model.ckpt.meta saved_model/
frozen_inference_graph.pb model.ckpt.index pipeline.config
위와 같이 export_inference_graph.py를 실행시키면 freeze 디렉토리에 frozen_inference_graph.pb 파일이 생성됩니다. 바로 이 파일이 이 글의 최종 결과물입니다.
적용
frozen_inference_graph.pb 파일과 pet_label_map.pbtxt 파일이 있으면 tensorflow-instance-segmentation에서와 동일한 방법으로 Webcam 동영상에서 개/고양이 품종을 인식할 수 있습니다. (object_detector.py). JPEG, PNG 등의 그림 파일에서 object를 인식하여 그림 파일로 저장하는 예제도 추가하였습니다. (image_detector.py)
$ mkdir -p ~/work/opencv
$ cd ~/work/opencv
$ git clone https://github.com/ukayzm/opencv.git
$ cd object_detection_tensorflow
$ mkdir pet
$ cp ~/work/pet-training/freeze/frozen_inference_graph.pb ./pet
$ cp ~/work/pet-training/data/pet_label_map.pbtxt ./data
$ python image_detector.py input.jpg -o output.jpg
$ python object_detector.py
아래 그림은 image_detector.py를 실행시킨 결과물 입니다.

Trouble Shooting
구글이 설명한 예제를 그대로 따라해 보면 여러 에러를 만나게 되는데, 에러에 대한 대처법을 아래와 같이 정리하였습니다.
ValueError
Training을 시키면, 아래와 같은 에러가 발생할 수 있습니다.
ValueError: Tried to convert 't' to a tensor and failed. Error: Argument must be a dense tensor: range(0, 3) - got shape [3], but wanted [].
이것은 Python version 때문에 발생하는 에러라고 합니다. 이 때는 ~/work/tensorflow/models/research/object_detection/utils/learning_schedules.py 파일을 아래와 같이 수정합니다. 168째 줄을 list()로 감싸는 것입니다.
167 rate_index = tf.reduce_max(tf.where(tf.greater_equal(global_step, boundaries),
168 list(range(num_boundaries)),
169 [0] * num_boundaries))
이 방법은 https://github.com/EdjeElectronics/TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10/issues/11를 참고하였습니다.
OutOfRangeError
OutOfRangeError (see above for traceback): FIFOQueue '_2_prefetch_queue' is closed and has insufficient elements (requested 1, current size 0)
이 에러는 input data를 읽을 수 없을 때 발생합니다. pet_train.record, pet_val.record 파일이 정상적으로 생성되었는지, 파라미터로 지정한 path가 틀리지는 않았는지, faster_rcnn_resnet101_pets.config에 지정한 경로는 정상인지 검토해 보세요.
contextlib2
Python을 실행시켰을 때, 아래와 같은 에러가 발생하면 contextlib2를 설치하세요.
ImportError: No module named 'contextlib2'
$ pip install contextlib2